“The only way of discovering the limits of the possible is to venture a little way past them into the impossible.” –
Clark’s Second Law
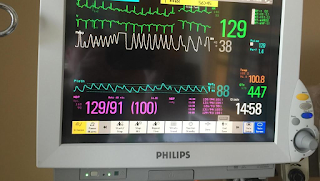
In the first blog post, Dr. Manthous invited Drs. Ely, Brochard, and Esteban to respond to a simple vignette about a patient undergoing weaning from mechanical ventilation. Each responded with his own variation of a cogent, evidence based, and well-referenced/supported approach. I trained with experts of similar ilk using the same developing evidence base, but my current approach has evolved to be something of a different animal altogether. It could best be described as a “trial of extubation”. This approach recently allowed me to successfully extubate a patient 15 minutes into a trial of spontaneous breathing, not following commands, on CPAP 5, PS 5, FiO2 0.5 with the vital parameters in the image accompanying this post (respiratory rate 38, tidal volume 350, heart rate 129, SpO2 88%, temperature 100.8). I think that any account of the “best” approach to extubation should offer an explanation as to how I can routinely extubate patients similar to this one, who would fail most or all of the conventional prediction tests, with a very high success rate.
A large part of the problem lies in shortcomings of the data upon which conventional prediction tests rely. For example, in the landmark
Yang and Tobin report and many reports that followed, sensitivity and specificity were calculated considering physicians’ “failure to extubate” a patient as equivalent to an “extubation failure”. This conflation of two very different endpoints makes estimates of sensitivity and specificity unreliable. Unless
every patient with a prediction test is extubated, the sensitivity of a test for successful extubation is going to be an overestimate, as suggested by
Epstein in 1995. Furthermore, all studies have exclusion criteria for entry, with the implicit assumption that excluded patients would not be extubatable with the same effect of increasing the apparent sensitivity of the tests.
Even if we had reliable estimates of sensitivity and specificity of prediction tests, the utility calculus has traditionally been skewed towards favoring specificity for extubation success, largely on the basis of a single
20-year old observational study suggesting that patients who fail extubation have a higher odds of mortality. I do not doubt that if patients are allowed to “flail” after it becomes clear that they will not sustain unassisted ventilation, untoward outcomes are likely. However, in my experience and estimation, this concern can be obviated by bedside vigilance by nurses and physicians in the several hours immediately following extubation (with the caveat that a highly skilled airway manager is present or available to reintubate if necessary). Furthermore, this period of observation provides invaluable information about the cause of failure in the event failure ensues. There need be no further guesswork about whether the patient can protect her airway, clear her secretions, maintain her saturations, or handle the work of breathing. With the tube removed, what would otherwise be a prediction about these abilities becomes an observation, a datapoint that can be applied directly to the management plan for any subsequent attempt at extubation should she fail – that is, the true weak link in the system can be pinpointed after extubation.
The specificity-heavy utility calculus,
as I have opined before, will fail patients if I am correct that an expeditious reintubation is not harmful, but each additional day spent on the ventilator confers incremental harm. Why don’t I think reintubations are harmful? Because when my patients fail, I am diligent about rapid recognition, I reintubate without observing complications, and often I can extubate successfully the next day, as I did a few months ago in a patient with severe ARDS. She had marginal performance (i.e., she failed all prediction tests) and was extubated, failed, was reintubated, then successfully extubated the next day. (I admit that it was psychologically agonizing to extubate her the next day. They say that a cat that walks across a hot stove will never do so again. It also will not walk on a cold stove again. This psychology deserves a post of its own.)
When I tweeted the image attached to this post announcing that the patient (and many like her) had been successfully extubated, there was less incredulity than I expected, but an astute follower asked – “Well, then, how do you decide whom and when to extubate?” I admit that I do not have an algorithmic answer to this question. Experts in opposing camps of decision psychology such as
Kahneman and his adherents in the heuristics and biases camp and
Gary Klein,
Gird Gigerenzer and others in the expert intuition camp could have a heyday here, and perhaps some investigation is in order. I can summarize by saying that it has been an evolution over the past 10 or so years. I use everything I learned from the conventional, physiologic, algorithmic, protocolized, data-driven, evidence-based approach to evaluate a patient. But I have gravitated to being more sensitive, to capture those patients that the predictors say should fail, and I give them a chance – a “trial of extubation.” If they fail, I reintubate quickly. I pay careful attention to respiratory parameters, mental status, and especially neuromuscular weakness, but I integrate this information into my mental map of the natural history of the disease and the specific patient’s position along that course to judge whether they have even a reasonable modicum of a chance of success. If they do, I “bite the bullet and pull it.”
I do not eschew data, I love data. But I am quick to recognize their limitations. Data are generated for many reasons and have different values to different people with different prerogatives. From the clinician’s and the patient’s perspective, the data are valuable if they reduce the burden of illness. I worry that the current data and the protocols predicated on them are failing to capture many patients who are able to breathe spontaneously but are not being given the chance. Hard core evidence based medicine proponents and investigators need not worry though, because I have outlined a testable hypothesis: that a “trial of extubation” in the face of uncertainty is superior to the use of prediction tests and protocols. The difficult part will be determining the inclusion and exclusion criteria, and no matter what compromise is made uncertainty will remain, reminding us that science is an iterative, evolving enterprise, with conclusions that are always tentative.

















